deAI - Part 2: Decentralized Training
Special thanks to Sam Kim, the team at FortyTwo Network (Vlad Larin, Alex Firsov, Ivan Nikitin), Travis Good (Ambient), Alexander Long (Pluralis), Dillon Rolnick (Nous Research) for incredibly valuable discussions, insights and feedback of this report.
If you are unfamiliar with the premise of how transformers work in the context of Machine Learning, please read through “Transformers 101” in order to better understand the rest of this report. Feel free to skip around the report as you choose, most sections are agnostic to each other until it all comes together at the very end of the report.
The Bottleneck
Hardware
The multi-headed attention mechanism in transformers, which scales linearly with context length, enables the processing of vast amounts of data in parallel. This groundbreaking approach, while highly efficient, demands extraordinarily large amounts of computational resources. Training large-scale models such as Llama 3 has already pushed boundaries by utilizing thousands of GPUs—estimates suggest around 24,000 GPUs for such tasks. Despite this, AI capabilities have seen relative stagnation since GPT-4's release, primarily because no one has significantly increased the compute dedicated to a single model.
Most models released after GPT-4, including Google's Gemini Ultra, Nvidia's Nemotron 340B, and Meta's Llama 3 405B, have operated at a similar level of training compute—approximately 2 x 10^25 FLOPs. Even though some of these models allocated equal or greater computational resources compared to GPT-4, they didn't unlock new capabilities due to less effective architectures.
The next step for AI is clear: training a multi-trillion parameter multimodal transformer (compared to 400 Billion parameter models today) capable of processing massive amounts of video, image, audio, and text data. While no one has achieved this yet, there's a surge of activity among major AI labs aiming to be the first.
Multiple large AI organizations—including OpenAI/Microsoft, xAI, and Meta—are racing to build GPU clusters exceeding 100,000 units. These clusters represent colossal investments, with server capital expenditures surpassing $4 billion. They're also constrained by datacenter capacity and power requirements, as GPUs generally need to be co-located for high-speed chip-to-chip networking. A 100,000-GPU cluster demands over 150 MW of datacenter capacity can consume approximately 1.59 terawatt-hours annually, costing around $123.9 million at a standard electricity rate of $0.078 per kWh.
To put this into perspective, OpenAI's GPT-4 was trained using about 1.33 x 10^23 FLOPs over 100 days on approximately 25,000 A100 GPUs, offering a peak throughput of 6.25 BF16 exaFLOPs per second. In contrast, a 100,000 H100 GPU cluster would provide a peak theoretical AI training throughput of 198 FP8 exaFLOPs per second—a 31.7× increase. With such computational power, training a model like GPT-4 could be accomplished in just three days using FP8 precision (FP8 meaning 8 bit floating point representation).
However, scaling up GPU clusters introduces significant challenges related to data transfer and communication efficiency. High-speed interconnects like NVIDIA's NVLink and networking solutions such as InfiniBand are critical for rapid data exchange between GPUs. Yet even these advanced interconnects can become bottlenecks at scale due to bandwidth and latency limitations. The immense volume of data that needs to be synchronized across thousands of GPUs strains these systems, potentially leading to underutilization of computational resources.
From an energy perspective, managing the power consumption and cooling requirements of such large clusters often necessitates dividing them into separate "islands" or data centers. These islands operate semi-independently and are connected using Ethernet networks. While this segmentation helps distribute the energy load and reduces strain on individual facilities, Ethernet offers lower bandwidth and higher latency compared to specialized interconnects like InfiniBand. This separation can exacerbate communication bottlenecks between clusters, impacting overall training efficiency.
Moreover, the limitations in datacenter capacity and power availability mean that co-locating GPUs becomes a logistical challenge. A 100,000-GPU cluster not only requires substantial electrical infrastructure but also poses significant cooling demands, as GPUs must be closely situated to facilitate high-speed networking.
The parallelizable structure of transformers facilitates the ingestion and processing of extensive datasets, but it also entails significant computational and energy demands. Addressing challenges associated with interconnect technology bottlenecks, along with managing energy consumption via strategic cluster partitioning, remains essential for enhancing the viability of large-scale AI training. An alternative approach that could circumvent these constraints is decentralized training.
Decentralized training holds the promise of unprecedented computational power by utilizing a global network of underutilized devices. This approach has been exemplified by the Folding@home project during the COVID-19 pandemic, which amassed a combined processing power of 2.4 exaFLOPS—approximately 15 times greater than that of the most powerful supercomputer at the time—by leveraging contributions from over 2 million volunteer devices. A similar example is the Bitcoin network, which operates a highly decentralized infrastructure, maintaining an immense hashrate of approximately 948.87 exahashes per second (EH/s). This demonstrates the feasibility of distributed, high-efficiency computation at a global scale. If such decentralized networks were to be repurposed for AI training, the resulting computational capacity could dramatically lower both the costs and the training durations for multi-trillion parameter models. Such a paradigm shift could democratize access to advanced AI capabilities and drive innovation in areas such as multimodal systems and edge AI applications.
A significant advantage of decentralized training lies in its capacity to manage thermal efficiency. In contrast to centralized GPU clusters that require expensive cooling systems, decentralized networks distribute computational workloads—and therefore heat—across multiple, geographically diverse locations. This distributed approach to model training inherently mitigates the need for extensive cooling infrastructure, resulting in considerable energy savings and improved sustainability. Alexander Long (founder of Pluralis) states in his article that “...not requiring close physical colocation of devices means that the cooling cost, which is typically ~40% of a datacenter operating expense, is completely removed” and that “there are several arguments for the cost effectiveness of decentralized training such as the ability to aggregate low-cost, low-capacity power sources, the lack of need for cooling, the relaxation of the high utilization constraint etc.”.
For more concrete context, training GPT-4 in Northern Sweden, where the energy mix yields emissions of just 17 gCO2eq per kWh, results in a carbon footprint equivalent to driving a car around the globe approximately 300 times[1]. Conversely, training the same model in Germany, where the energy mix is more carbon-intensive, would have an environmental impact equivalent to 30 cars making the same journey. By leveraging decentralized training, which allows the selection of locations with cleaner or more efficient energy sources, both the carbon footprint and the overall costs of model training can be significantly reduced. This strategic geographic flexibility not only minimizes environmental impacts but also promotes more sustainable and cost effective AI development practices[2].
A Brief Look at Hardware Innovations
To meet these escalating computational demands and overcome current limitations, the industry is exploring alternative hardware solutions beyond traditional GPUs. Innovations such as Field-Programmable Gate Arrays (FPGAs), Tensor Processing Units (TPUs), and neuromorphic chips are emerging as promising technologies to accelerate AI training and inference while improving energy efficiency.
FPGAs offer a flexible hardware platform that can be reprogrammed to optimize specific computational tasks. Their ability to be customized for particular workloads makes them attractive for specialized AI applications. In decentralized training environments, FPGAs can be configured to handle specific neural network operations more efficiently than general-purpose GPUs. They also offer lower latency and can be more energy-efficient for certain tasks, which is crucial when managing the power constraints of large-scale clusters.
Tensor Processing Units (TPUs), developed by Google, are application-specific integrated circuits designed specifically for machine learning tasks. TPUs excel at handling large-scale matrix and vector operations that are common in neural network training and inference. Their architecture allows for high throughput and improved performance per watt compared to traditional GPUs. TPUs have been instrumental in powering some of the largest AI models to date and are a key component in Google's strategy to advance AI capabilities while managing energy consumption and hardware costs.
Neuromorphic chips represent a radical departure from conventional computing architectures. Inspired by the human brain, these chips use spiking neural networks to process information in a way that mimics biological neurons and synapses. Neuromorphic hardware has the potential to perform complex computations with significantly lower power consumption, making them ideal for edge computing and scenarios where energy efficiency is paramount. While still in the experimental stage for large-scale AI training, neuromorphic chips could offer novel approaches to overcoming the limitations of current hardware.
Summary
There are many difficulties with scaling AI models; These include communication overhead across different data centers, energy costs for high powered data centers, and interconnect costs for islands of GPU clusters. These challenges can’t be addressed with just hardware development, and also favor rich and powerful companies.
The United States owns 5,500 data centers, which is more than the next 10 countries combined. This centralization can lead to several issues, including data sovereignty challenges, unequal access to AI technologies, and increased vulnerability to regional disruptions or geopolitical tensions. When the majority of AI infrastructure is located in one country, it can limit participation from other regions and create dependencies that hinder global collaboration and innovation.
So in the next sections, we will explore software/architecture progress that has been made in speeding up these models. The end goal is to achieve highly efficient and scalable distributed training.
Resources for More In Depth Understanding
- A deep dive on scaling data centers
- What is a GPU: intel
- The Role of GPUs In ML: Telnyx
- AI Infrastructure Explained: Salesforce
Accelerating Model Training
As discussed in the hardware section, not only is there a need for distributed training by sheer size requirements, there is also a need for distributed training for global equity in access to AI. The following sections will deep dive into various research that has been done in order to make this possible. We will take a look at the different types of parallelism used to achieve training of the models we have today. Next, we will explore the latest research that highlights our advancements and demonstrates how decentralized AI is actually feasible.
A Quick Recap on Model Training:
Models are trained on vast amounts of data, this is done by passing it through the initially randomized weights of the model, and computing a loss function. This loss function allows us to backpropagate through the model and nudge all the weights in the right direction to minimize loss.
Key Terms:
- Backpropagation: The process by which weights are updated in a model.
- Loss Calculation: A numerical calculation of how far off your output is from the desired output.
- Weights: The numbers inside a transformer model, essentially the numbers used for the additions and multiplications throughout the model.
- Temperature: When we calculate the output prediction of the model, temperature allows us to control how open we want to be to selecting lower probability outputs. This essentially allows the model to be more creative and give different responses.
- Learning Rate: When we backpropagate we nudge the weights in the right direction, the learning rate is the amount of nudging we do.
- Pre Training: We start with models that have no understanding of any human language, this phase is called pre-training.
- Fine Tuning: This is the phase of training where we get a token prediction model to become a question answering model. It changes the behavior of the model more then the information.
- Few Shot Learning: The idea that it only takes a few iterations to fine tune a model to change its behavior. Paper.
- Layers: This refers to the parts of the transformer we mentioned before, multiheaded attention is a layer, Feed Forward Neural Network is a layer etc.
- Federated Learning: The idea that we can train models on data across different devices, and then sync those weights together later. This allows us to train on private data sets without releasing any private information.
Overview on Parallelism
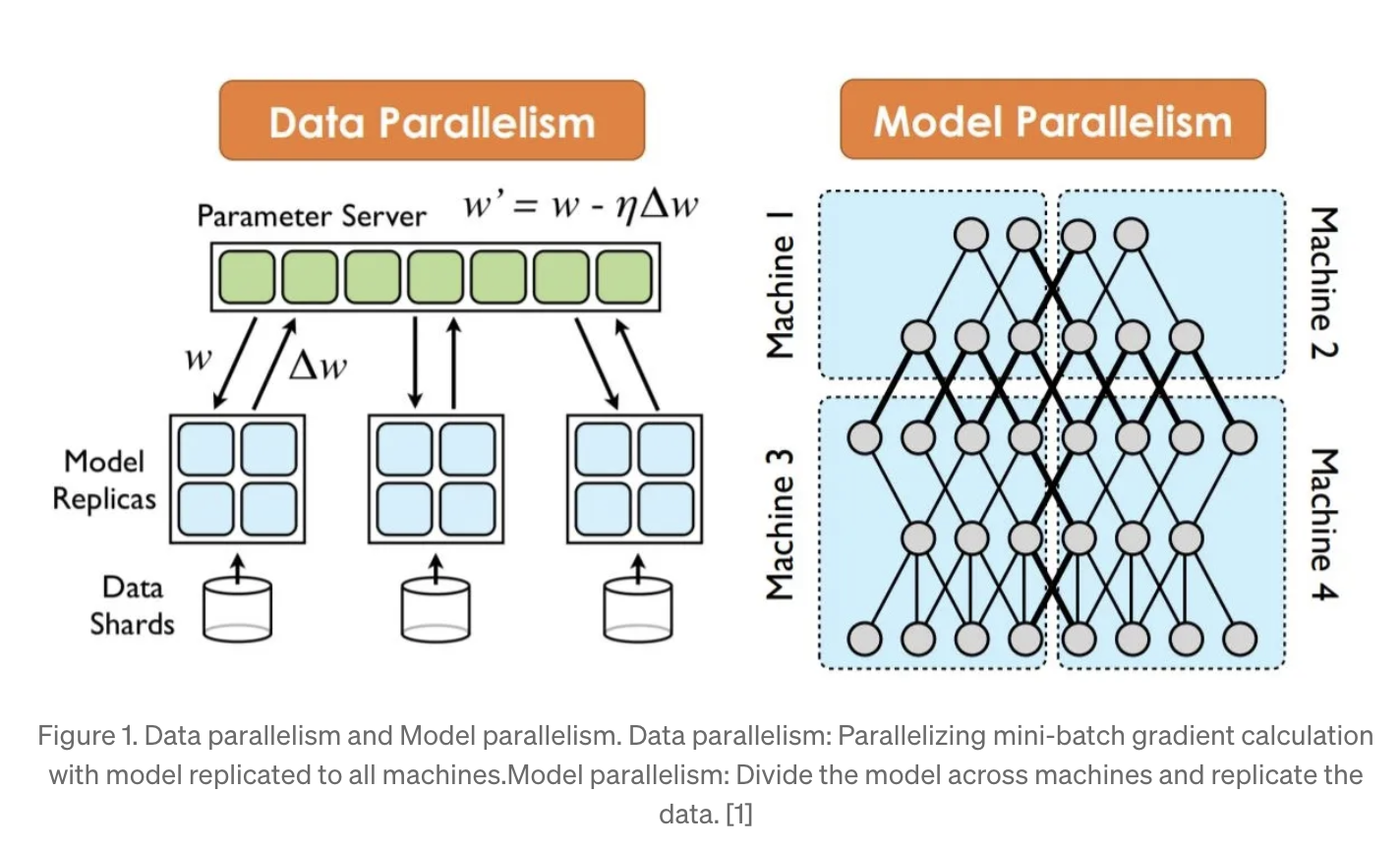
There are three main types of parallelism in distributed computing: Data Parallelism, Tensor Parallelism, and Pipeline Parallelism. Model Parallelism is a hybrid approach that combines Pipeline and Tensor parallelism.
Referring to the image above: Pipeline Parallelism divides the model horizontally, splitting it into sequential sections such as the top and bottom halves. Meanwhile, Tensor Parallelism splits the model vertically, partitioning layers into sections like the left and right halves[3].
Each method introduces unique challenges and implementation considerations, which will be discussed in detail in the following sections.
Data Parallelism
In data parallelism, we keep identical copies of our entire model on several GPUs or machines. Each device processes a different batch of data, computes the loss, and updates the weights accordingly. After each training step, we synchronize the weights across all devices to ensure consistency. This method accelerates training without increasing the memory requirement per device since each holds the full model. However, because each device must store the entire model, this approach becomes impractical for extremely large models that exceed individual memory capacities.
Tensor Parallelism
To overcome the memory limitations of data parallelism, we turn to tensor parallelism. Here, we split the model's tensors—like weights and activations—across multiple devices. Each device is responsible for computing a portion of the operations within each layer. For example, during a matrix multiplication, each GPU computes a slice of the result. This reduces the memory burden on individual devices, allowing us to train much larger models. The trade-off is that devices need to frequently communicate intermediate results, which can slow down training if the interconnects aren't fast enough.
Pipeline Parallelism
Pipeline parallelism takes a different approach by dividing the model's layers among multiple devices. Think of it like an assembly line: the first device processes its assigned layers and passes the output (activations) to the next device, which processes the next set of layers, and so on. This method spreads the model across devices, significantly reducing the memory required per device. However, it can introduce idle times—known as "pipeline bubbles"—when devices are waiting for data from earlier stages. We often use micro-batching and careful scheduling to keep all devices busy and minimize these delays.
Deep Dive into Pipeline Parallelism

To keep things straightforward, we will focus on the decoder section of a transformer, as illustrated on the right. Each block is clearly divided into layers, with values being passed from one layer to the next. You’ll also notice a small “Nx” next to the block, which indicates how many times that block is repeated. Typically, during training, this transformer block is repeated several times. As previously mentioned, the core concept behind pipeline parallelism is to distribute these layers across different devices, optimizing the training process.
GPIPE
Please see here for the GPIPE paper.
The first paper released on pipeline parallelism took a rather naive approach. It just simply separates each layer onto a different device. This was mostly used in order to work on models that couldn’t fit within one accelerator (GPU). Let's consider an example with 7 stages (accelerators) and 12 micro-batches:
Forward Pass Timeline:
- Time Step 1:
- Accelerator 1 processes micro-batch 1.
- Time Step 2:
- Accelerator 1 processes micro-batch 2.
- Accelerator 2 processes micro-batch 1.
- Time Step 3:
- Accelerator 1 processes micro-batch 3.
- Accelerator 2 processes micro-batch 2.
- Accelerator 3 processes micro-batch 1.
- ...
- Time Step 7:
- All accelerators are processing different micro-batches.
- Time Steps 8-18:
- Micro-batches continue to flow through the pipeline until all 12 micro-batches have completed their forward passes.
Backward Pass Timeline:
- Pipeline Flush:
- No new micro-batches are introduced.
- Time Step 19:
- Accelerator 7 starts the backward pass for micro-batch 12.
- Time Step 20:
- Accelerator 7 processes micro-batch 11.
- Accelerator 6 processes micro-batch 12.
- ...
- Time Step 25:
- Accelerators process backward passes for remaining micro-batches.
- Completion:
- All micro-batches have completed their backward passes.
Weight Update:
- After Time Step 25, gradients are aggregated.
- Weights are updated synchronously across all accelerators.
GPIPE has several limitations, one of the most notable being pipeline flushing, which is highly inefficient. It requires waiting for all forward passes to complete, introducing significant overhead. To address these inefficiencies, Google conducted further research and subsequently released a paper titled “PipeDream,” which presents an improved approach to pipeline parallelism.
PipeDream
PipeDream aims to optimize resource utilization and improve training throughput by keeping all accelerators consistently busy without the need for frequent synchronization.
Key Differences in PipeDream:
- Asynchronous Weight Updates:
- PipeDream allows for asynchronous weight updates across different pipeline stages.
- Each micro-batch can use a different version of the model weights, enabling continuous flow of data through the pipeline without waiting for all stages to synchronize.
- Weight Stashing:
- During the forward pass, each micro-batch's input is tagged with the version of the weights it used. This same version is then used during the backward pass to ensure consistency in gradient computation.
- Interleaved Execution:
- PipeDream schedules micro-batches in a way that different pipeline stages process different micro-batches simultaneously, maximizing hardware utilization.
- By overlapping the computation of forward and backward passes across different micro-batches, it reduces idle times for accelerators.
- Efficient Memory Management:
- PipeDream optimizes memory usage by only keeping necessary weight versions that are actively used by in-flight micro-batches.
Execution Timeline in PipeDream:
- Forward Pass:
- Each accelerator processes incoming micro-batches using the latest available weights.
- Backward Pass:
- Accelerators perform the backward pass using the same version of weights that were used during the corresponding forward pass, thanks to weight stashing.
- Gradients computed are consistent with the weights used, ensuring correct training updates.
- Weight Updates:
- After completing the backward pass for a micro-batch, gradients are applied to update the weights asynchronously.
PipeDream significantly improves upon GPIPE by eliminating pipeline flushing, which increases the number of micro-batches processed and keeps all accelerators continuously engaged. Its use of asynchronous execution and interleaving of micro-batches reduces idle times for accelerators. Lastly, PipeDream scales effectively with the number of accelerators, making it well-suited for training very large models in distributed computing environments.
Conclusion and Further Research on Pipeline Parallelism
Since the developments in PipeDream, pipeline parallelism has made several key improvements. One major advancement is PipeDream-2BW, which addresses the weight staleness issue present in the original PipeDream by introducing bidirectional weight updates. This just allows the weights to be updated even more often resulting in faster convergence. Convergence in this case is again that valley in the gradient descent diagram we mentioned.
Lastly, the integration of automatic parallelism planning and compiler-based optimizations has made pipeline parallelism more accessible and effective in practical applications. Tools like Alpa and compiler enhancements in XLA automate the partitioning of models and the scheduling of micro-batches, optimizing computation and communication without requiring extensive manual tuning. These advancements collectively contribute to better hardware utilization and the ability to train increasingly larger models efficiently.
There is active research being done in this area, but most of the developments are in combining the three different types of parallelism which we will discuss later.
Readings and Sources for this Section
- GPIPE: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- PipeDream: Generalized Pipeline Parallelism for DNN Training
- PipeDream-2BW: Improving Pipeline Parallelism for DNN Training via Bidirectional Weight Updates
Deep Dive into Tensor Parallelism
1. Partitioning Weight Matrices
The core idea behind tensor parallelism is splitting the large weight matrices across multiple GPUs. Let's take the example of a fully connected layer in a transformer model:
- Suppose you have a fully connected layer with a weight matrix W of size [DInput, DOutput]where DInput is the input dimension and DOutput is the output dimension.
- In tensor parallelism, this matrix is partitioned along the output dimension. For example, if you have 4 GPUs, each GPU stores a portion of the matrix: W1,W2, W3, and W4, where each sub-matrix Wi is of size [DInput, DOutput/4].
2. Forward Pass with Tensor Parallelism
During the forward pass:
- The input x to the fully connected layer (which has a dimension of DInput) is broadcast to all GPUs.
- Each GPU performs a matrix multiplication of the input x with its portion of the weight matrix Wi.
- Once the local computation is done, the results (partial outputs) from all GPUs are gathered. This creates the full output of the layer by concatenating the partial results across GPUs.
3. Backward Pass with Tensor Parallelism
The backward pass works similarly, with gradients being partitioned and recombined:
- The gradient with respect to the output of the layer is scattered across the GPUs. Each GPU computes the gradient with respect to its own partition of the weight matrix.
- Gradients from the local matrices Wi are then aggregated to update the full weight matrix.
The key operation here is all-reduce, where gradients from all GPUs are summed and synchronized. Each GPU uses this all-reduced gradient to update its local portion of the weights.
Summary
Tensor parallelism is essentially mathematically splitting tensors across different devices. The benefits of it are limited because it requires high interconnect speeds between hardware since matrices have to be synced at every step. Therefore, most approaches that use this within clusters use other forms of parallelism to achieve further efficiencies.
Deep Dive on Data Parallelism
In data parallelism, the model architecture and its parameters are copied across all participating devices. The training dataset is partitioned into mini-batches, and each device receives a unique mini-batch to process during each training iteration. This approach allows for parallel computation of forward and backward passes, effectively utilizing the computational resources available.
Key Steps in Data Parallel Training:
- Forward Pass: Each device performs a forward pass using its mini-batch and the local copy of the model parameters.
- Loss Computation: The loss is computed locally on each device based on its output and the ground truth labels.
- Backward Pass: Each device computes the gradients of the loss with respect to the model parameters.
- Gradient Synchronization: Gradients are averaged (or summed) across all devices to ensure consistency.
- Parameter Update: All devices update their model parameters using the synchronized gradients.
Synchronous Data Parallelism:
In synchronous data parallelism, all devices wait at the synchronization point after the backward pass to exchange gradients. This ensures that all model replicas remain consistent across devices.
- Advantages:
- Model Consistency: All devices use the same model parameters for each iteration, leading to consistent convergence behavior.
- Deterministic Behavior: Training results are reproducible since updates are synchronized.
- Disadvantages:
- Straggler Problem: The overall training speed is limited by the slowest device. If one device is delayed, all others must wait.
- Scalability Limitations: Communication overhead increases with the number of devices, potentially reducing efficiency.
Asynchronous Data Parallelism:
Asynchronous data parallelism allows devices to compute and update model parameters independently without waiting for others.
- Advantages:
- Improved Resource Utilization: Devices do not idle while waiting for synchronization
- Fault Tolerance: The system can handle devices dropping in and out
- Disadvantages:
- Stale Gradients: Devices may use outdated parameters, leading to possible inconsistencies and slower or unstable convergence.
- Complexity in Convergence Analysis: The asynchronous nature makes theoretical guarantees on convergence more challenging.
Convergence in this case simply means reaching the weights and biases necessary to minimize the loss function.
Gradient Synchronization Mechanisms
After completing the forward pass across distributed GPUs, the gradients must be synchronized across these devices. In the following sections, we will explore various synchronization mechanisms used to achieve this efficiently.
All-Reduce Operations
At the end of the forward pass during synchronous distributed training, the all-reduce operation allows for the devices to synchronize on the average of the gradient updates they all made during that step of training.
- Implementations:
- Ring All-Reduce: Devices are organized in a ring topology, and gradients are passed along the ring in both directions, reducing communication overhead.
- Tree All-Reduce: Gradients are aggregated in a hierarchical tree structure, suitable for larger numbers of devices.
Parameter Servers
In distributed training, a parameter server architecture can manage gradient aggregation. Centralized parameter servers collect gradients from all devices, compute the average, and update the global model parameters. This approach can create bottlenecks, limiting scalability.
Distributed parameter servers address this issue by spreading the load across multiple servers, allowing devices to communicate with different servers and improving scalability by reducing bottlenecks.
Communication overhead is a significant challenge in distributed training, particularly as the number of devices increases. To mitigate this, strategies such as gradient compression using techniques like quantization, sparsification, and top-k selection reduce the data exchanged during synchronization, though these methods may introduce approximation errors that affect convergence. Gradient accumulation is also used to decrease the frequency of communication, though it may require adjustments to learning rates and can influence convergence dynamics.
Summary
Several deep learning frameworks provide built-in support for data parallelism, making it easier to implement and manage distributed training. Pytorch DDP, Horovod, and TensorFlow’s mirrored strategy are all good libraries to dive deeper into if you want to do further research on data parallelism.
Data Parallelism is the most widely used, and most important form of parallelism when it comes to model training.
3D Parallelism: A Combination of All Three
Even with the types of parallelism discussed above, models have continued to grow and need every type of optimization possible. Researchers have introduced 3D parallelism, to deal with this growth, which is essentially a combination of the techniques we have discussed thus far. One of the most notable implementations of 3D parallelism is Megatron-LM, developed by NVIDIA, which has been instrumental in training some of the largest transformer models to date, and is the technique used to train NVLM 1.0 released yesterday. NVLM is an open source 70.5 billion parameter model that outperformed Llama 400B.
Megatron-LM and 3D Parallelism
Megatron-LM is a framework designed to efficiently train large transformer models by leveraging the strengths of data, tensor, and pipeline parallelism simultaneously.
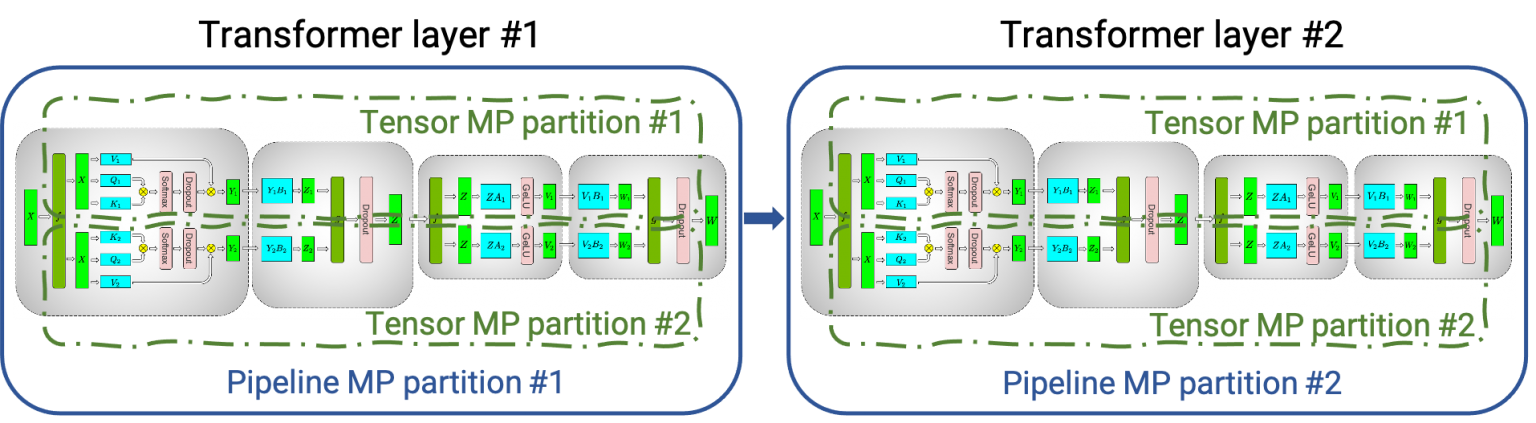
How 3D Parallelism Works in Practice
In a typical 3D parallelism setup with Megatron-LM:
- GPU Organization: GPUs are arranged in a 3D grid where each dimension corresponds to one of the parallelism strategies. For example, in a system with 64 GPUs, you might have 4 data-parallel groups, each containing 4 pipeline stages, with each stage consisting of 4 GPUs for tensor parallelism.
- Training Process:
- Data Parallel Axis: Each data-parallel group works on different subsets of the data.
- Tensor Parallel Axis: Within a pipeline stage, computations for each layer are split among GPUs, allowing the handling of large models that wouldn't fit into a single GPU's memory.
- Pipeline Parallel Axis: Micro-batches of data are passed through the pipeline stages. While one micro-batch is being processed in one stage, other micro-batches are processed in other stages, keeping the pipeline full and GPUs busy.
- Communication Optimization: Megatron-LM carefully schedules communication to overlap with computation wherever possible. High-speed interconnects and optimized collective communication operations are used to reduce latency.
Recent Advances and Other Works
Beyond Megatron-LM, several other frameworks and research efforts have contributed to the advancement of 3D parallelism:
- DeepSpeed by Microsoft: DeepSpeed introduces the Zero Redundancy Optimizer (ZeRO), which partitions model states (optimizer states, gradients, and parameters) across data-parallel processes to reduce memory redundancy. Combined with 3D parallelism, DeepSpeed enables training models with trillions of parameters by efficiently utilizing both memory and computational resources.
- PipeDream-3D: Building upon the PipeDream pipeline parallelism framework, PipeDream-3D integrates data, model (tensor), and pipeline parallelism. It focuses on balancing memory usage and communication overhead while providing efficient scheduling algorithms to maximize hardware utilization and minimize pipeline stalls.
- FairScale by Facebook AI Research: FairScale is a PyTorch extension that provides a suite of tools for mixed parallelism strategies, including 3D parallelism. It offers features like Sharded Data Parallelism, which reduces memory usage by sharding optimizer states and gradients, and integrates seamlessly with existing PyTorch models.
- TeraPipe: TeraPipe proposes methods for training trillion-parameter models by combining tensor and pipeline parallelism. It emphasizes reducing communication volume and latency through techniques like selective activation recomputation and optimized cross-stage communication.
Challenges and Considerations
While 3D parallelism offers a pathway to training ultra-large models, it introduces several challenges which we can see below:
- Communication Overhead: Coordinating between data, tensor, and pipeline parallel groups requires extensive communication. Optimizing communication patterns and utilizing high-bandwidth, low-latency interconnects (like NVIDIA's NVLink or InfiniBand) are crucial to prevent communication from becoming a bottleneck.
- Complexity in Implementation: Combining three forms of parallelism increases the complexity of the training infrastructure. Effective tooling and abstractions are necessary to manage this complexity, which frameworks like Megatron-LM and DeepSpeed aim to provide.
- Load Balancing: Ensuring that all GPUs are effectively utilized requires careful partitioning of both the model and the workload. Imbalanced workloads can lead to idle GPUs and reduced training efficiency.
- Debugging and Reproducibility: The added complexity can make debugging more challenging. Ensuring reproducibility across runs may require meticulous control over random seeds and synchronization points.
What Does This Mean for deAI?
Understanding these different forms of parallelism is important because it allows us to understand the upper limit of what we can achieve with consumer devices. All of the research we’ve covered thus far has been driven by centralized organizations, aiming to optimize the use of high-performance hardware at their disposal. These work in a decentralized manner but refer mostly to co-located GPU farms that are connected using high speed interconnect. There are two places where this fails. First, due to densely colocated GPU farms, the energy cost and overhead skyrockets. Second, access to these farms is reserved for giants like Nvidia, Meta, Apple, Amazon, and Microsoft.
Within deAI, there needs to be an efficient way to reduce the communication overhead created by 3D Parallelism. These forms of parallelism are the building blocks for research on deAI going forward. In the following section, we will take an in-depth look at recent research advancements within the crypto industry that reveal promising developments that enable deAI.
deAI: Crypto Research
deAI ideally reduces the communication overhead of 3D parallelism enough to achieve training in a feasible time and in a distributed manner. By distribution, we are referring to GPUs that are residing within data centers and households all over the world, not distribution across a GPU farm owned by a multinational company. There are two primary innovations we will cover in this section, DiLoCo and Distro. DiLoCo is a paper by Google DeepMind that was further researched by Prime Intellect, and shows promise in reducing the communication overhead by approx. 500x. Distro is a paper released by Nous Research that dives into a new optimizer that enables a 1000x reduction in communication overhead. Both of these approaches are not mutually exclusive and could be used in combination to achieve almost a 500,000x reduction in communication overhead–making it feasible to train LLMs in a decentralized manner. Following these innovations in training a standard transformer model, we will explore other architectures that may be more synergistic with crypto.
In order to understand these two papers, here is a quick intuitive recap on how transformers work, as well as how optimizers work.
Recap: How Transformers Work
Transformers are at the core of modern natural language processing models. The fundamental idea behind transformers is the use of an attention mechanism, which allows the model to weigh the importance of different parts of the input sequence when making predictions. Instead of processing input sequentially like RNNs, transformers process the entire sequence in parallel, which allows for more efficient computation.
A transformer architecture is composed of an encoder and a decoder, or sometimes just stacks of encoders for many NLP tasks. Within each encoder, there are multiple layers containing self-attention and feed-forward networks. The self-attention mechanism calculates the relationships between each word in the sequence, enabling the model to capture dependencies regardless of their distance within the text. This, paired with positional encodings to retain the order of information, provides transformers with their exceptional performance in capturing context.
In a distributed context, training transformers can be extremely communication-heavy. Every layer's attention mechanism and feed-forward component involves considerable synchronization across different GPUs, which results in high communication overhead. The more GPUs involved, especially across geographically distributed systems, the higher this overhead becomes, often making the task impractical. This is where DiLoCo and Distro aim to innovate.
Recap: How Optimizers Work
Optimizers are algorithms used to adjust the weights of neural networks to minimize the loss function. The most common optimizers include stochastic gradient descent (SGD) and its variants, like Adam and RMSProp. These methods work by computing gradients of the loss with respect to each weight and updating the weights accordingly.
To understand this intuitively, imagine you are trying to find the lowest point in a mountainous landscape (the minimum of the loss function). Gradient descent is like taking small steps downhill, always moving in the direction that produces the steepest descent. Each step is guided by the slope of the terrain (the gradient), and optimizers determine how big each step should be and how to adjust direction if the terrain becomes unpredictable.
- SGD: Stochastic Gradient Descent takes a step in the direction of the steepest descent, but it does so using a small, random subset of the data. Imagine you're hiking down the mountain but only using a flashlight to see a small part of the path at a time. This randomness can make your path bumpy and noisy, but it also helps you avoid getting stuck in small valleys (local minima) since the randomness can push you out of them.
- Adam: Adam can be thought of as a more adaptive version of SGD. It keeps track of the gradients over time and adjusts the learning rate for each weight individually. Imagine Adam as having a memory of the terrain you've already traversed. It remembers which directions were steeper or flatter, allowing it to make more informed decisions on how big a step to take and in which direction. This is like having both a map and an understanding of how steep different parts of the mountain are, helping you converge to the lowest point more quickly and smoothly. If SGD is like stumbling down with a flashlight, Adam is like using both a flashlight and a compass that remembers the steepest paths you've taken, allowing you to make smoother progress toward the goal.
- RMSProp: RMSProp modifies SGD by dividing the learning rate by a moving average of the recent magnitudes of the gradients. This helps prevent oscillations in the path down the hill, especially in areas where the slope changes direction frequently. It's like adjusting your steps based on how rocky or smooth the ground has been recently, ensuring you don't take overly large steps on uneven terrain that might make you stumble back and forth.
However, traditional optimizers like Adam and SGD require frequent gradient synchronization, which can cause massive delays when GPUs are spread across different regions globally. This is the key problem that Distro attempts to solve. Distro introduces a new optimization algorithm designed to reduce the frequency and size of communication between nodes, making distributed training feasible at a much larger scale.
Lowering Communication Overhead
DiLoCo: Reducing Communication Overhead by 500x
DiLoCo, which stands for "Distributed Local Coordination," introduces an innovative approach to handling communication between distributed GPUs. Instead of requiring global synchronization for every training step, DiLoCo focuses on a localized consensus mechanism where each node only communicates with a subset of other nodes. This drastically reduces the overall communication load. Additionally, DiLoCo leverages predictive modeling to anticipate and share key parameters, further decreasing the need for real-time synchronization. The research shows that these methods combined can yield up to a 500x reduction in communication overhead.
One of the key features of DiLoCo is its use of hierarchical clustering, where GPUs are grouped based on their proximity and communication capacity. Each cluster processes data semi-independently, and only critical information is exchanged across clusters. This allows distributed nodes across the world to cooperate effectively without overwhelming network resources.
DiLoCo relies on a dual-optimizer setup involving an inner and an outer optimizer. The inner optimizer, typically AdamW, is responsible for performing local updates on the model's parameters at each worker node independently. During each training step, each GPU performs local optimizations without communicating with other GPUs, allowing it to progress with minimal latency. After several local steps, the outer optimizer, usually using Nesterov momentum, comes into play. The outer optimizer aggregates the changes made by each local optimizer across nodes and updates a global version of the model.
This aggregation happens only after many inner steps, drastically reducing the frequency of synchronization compared to traditional approaches. The outer optimizer essentially acts as a coordinator, averaging out the local updates and synchronizing model parameters across nodes, ensuring the model converges without requiring constant communication.
The OpenDiLoCo framework, an open-source implementation by Prime Intellect, further enhances DiLoCo’s applicability to real-world decentralized environments. Built using the Hivemind library, OpenDiLoCo has successfully demonstrated the effectiveness of DiLoCo on a large scale, training models across continents with 90-95% compute utilization. The framework enables low-bandwidth distributed training, where nodes are connected using poorly connected internet links rather than high-speed dedicated lines. Notably, OpenDiLoCo also supports on/off ramping of resources, allowing nodes to join or leave dynamically without disrupting training. This makes it feasible to utilize any available computing resource, even those prone to disconnections, in the training process.
A key highlight of OpenDiLoCo is its pseudo-gradient calculation process, where each worker maintains two copies of the model: the main model being updated locally and a copy of the original weights. The difference between the locally updated model and the original model is computed as a pseudo-gradient, which is then used to adjust the global model during synchronization. This approach has been shown to be effective even when using FP16 precision, further reducing communication bandwidth requirements without degrading performance. The framework also features fault tolerance, meaning that even if some nodes fail or lose connectivity, the training process continues, which is crucial for truly decentralized environments.
Distro: Optimizer for Decentralized Training
Distro, developed by Nous Research, introduces an optimization method that seeks to further tackle the communication challenge by reducing the frequency of gradient updates that need to be shared across nodes. Unlike traditional optimizers that synchronize gradients after each mini-batch, Distro employs a form of adaptive delay mechanism, meaning that nodes only share their updates when significant changes have occurred. This reduces communication overhead by up to 1,000x.
The Distro optimizer leverages a novel compression technique that allows gradients to be shared in a highly compressed form, focusing on the most impactful updates while discarding redundant information. The adaptive delay combined with gradient compression makes Distro particularly well-suited for decentralized AI, where communication latency and bandwidth are the primary bottlenecks.

Combining DiLoCo and Distro: Towards Decentralized Training Feasibility
The true power of DiLoCo and Distro comes from their potential synergy. By combining DiLoCo's reduction of synchronization needs with Distro's communication-efficient optimizer, it is possible to achieve an almost 500,000x reduction in communication overhead. This magnitude of improvement could make training large-scale models feasible even when GPUs are scattered in data centers and households worldwide. Such an achievement would be a significant step towards fully decentralized AI, enabling individuals to contribute their hardware resources to a global AI training effort without suffering the typical pitfalls of high communication overhead.
Exploring Alternative Transformer Architectures
Beyond standard transformer architectures, there are potential opportunities to develop or adopt alternative architectures that may better align with the requirements of decentralized training and crypto-based incentives. For instance, architectures like sparse transformers or mixture-of-experts could be inherently more efficient for distributed setups by reducing the number of active parameters at each training step, thus minimizing communication.
In this section, we explore three alternative transformer architectures: Mixtral, Switch Transformers, and DiPaCo, and look at how they could be integrated into decentralized training environments, focusing on both their technical feasibility and their synergy with crypto-based incentives.
Mixtral
Mixtral 8x7B is a Sparse Mixture of Experts (SMoE) language model that brings efficiency and scalability by using a sparse mixture of experts at each layer. Essentially, Mixtral is like Mistral 7B (a standard transformer) but with a twist: instead of each layer having just one feedforward block, Mixtral has eight, which we call "experts." When the model processes a token, it doesn’t use all eight experts. Instead, a router selects two of these experts to handle the token at each layer, and these experts can change for each new token. This means that while Mixtral has access to 47B parameters, only 13B are actively used during inference, making it a lot more efficient.
This selective activation makes Mixtral an ideal candidate for decentralized training, because each token only interacts with a subset of experts, reducing both the computational load and communication needs for each training step. In decentralized systems, reducing communication is key to keeping things efficient. Mixtral also performs very well across benchmarks in areas like math, coding, and multilingual tasks, even when using fewer active parameters.
In a crypto-based system, the way Mixtral assigns experts to tasks could align nicely with incentives. Different nodes could be rewarded for contributing resources to train or maintain specific experts. Nodes that specialize in particular experts could get rewards based on how much their expert contributes to the model’s performance. This could lead to a market-driven training ecosystem, where nodes dynamically take on tasks based on both their capacity and the network's needs.
Switch Transformers
Switch Transformers are another take on Mixture of Experts that aim to simplify and make things more efficient. Instead of selecting two experts per token like Mixtral, Switch Transformers use only one expert per layer, which makes the routing mechanism simpler and reduces computational overhead even further. This makes them highly efficient for large-scale decentralized setups where the goal is to minimize communication and computational costs.
In a decentralized training context, Switch Transformers offer a great balance between model power and efficiency. Because only one expert is active per layer, there’s less communication overhead between nodes, which makes it easier to specialize nodes for specific experts. The nodes can be incentivized economically for maintaining and training their assigned experts, and because the workload per node is smaller, the resource requirements are lower. This structure could foster a scalable incentive model where contributors are rewarded based on their expert’s utility and specialization, thus driving more efficient resource allocation.
DiPaCo: Distributed Path Composition
DiPaCo (Distributed Path Composition) takes a different approach, using a modular and compositional method to transformer training. Instead of activating the entire model or all experts, DiPaCo constructs a model from shared modules and distributes training across multiple paths through these modules. Each path is essentially a different way of combining the shared modules, and during inference, only a single path is activated. This keeps memory and compute requirements lower compared to fully dense models.
DiPaCo is especially well-suited for decentralized training because of its modular design and how it reduces communication. Each node can independently train its assigned path, and communication between nodes is limited to occasional synchronization of shared modules, which means less frequent and lower-volume data exchanges. This is a huge advantage over fully synchronized training. Moreover, DiPaCo is resilient to nodes dropping out, which is perfect for decentralized environments where availability might vary.
Swarm Parallelism: Robust Training on Unreliable Networks
Swarm Parallelism is a completely different approach to decentralized training focused on pipeline parallelism rather than data parallelism like DiLoCo and Distro. The approach is meant to address the challenges of training a model with heterogeneous, unreliable, and poorly connected devices. In decentralized AI the majority of the bottlenecks as we have discussed previously stem from communication and reliability.
Key Principles of Swarm Parallelism
Stochastic Wiring of Pipelines
Swarm Parallelism replaces the rigid pipeline structures of traditional model-parallel training with temporary, randomized pipelines. Each node in the network can dynamically connect with others to form a pipeline stage, processing portions of the model's computation graph. This stochastic wiring allows the system to adapt to node failures or network variability without significant overhead.
Adaptive Rebalancing
The approach includes an adaptive rebalancing mechanism that redistributes computational workloads across nodes in response to changes in network conditions or node availability. If a node becomes a bottleneck due to failure or slow performance, Swarm Parallelism can reassign its tasks to other nodes, maintaining optimal throughput and utilization across the network.
Communication Efficiency
Swarm Parallelism leverages the Square-Cube Law of Distributed Training, which observes that as the model size increases, computation time grows faster than communication time. This principle implies that for sufficiently large models, the relative communication overhead diminishes, making it feasible to train large-scale models even over slow or unreliable networks.
To further enhance communication efficiency, Swarm Parallelism can incorporate compression techniques such as 8-bit quantization of activations and gradients. By reducing the size of data exchanged between nodes, the approach minimizes bandwidth requirements without significantly impacting model accuracy.
Benefits for Decentralized Training
Swarm Parallelism offers several advantages that make it particularly well-suited for decentralized AI training environments:
- Fault Tolerance: The stochastic and adaptive nature of the pipelines allows the system to continue functioning effectively even when nodes fail or disconnect.
- Heterogeneity Support: It efficiently utilizes devices with varying computational capabilities and network speeds, assigning workloads based on real-time performance metrics.
- Low Bandwidth Requirements: By reducing communication overhead, Swarm Parallelism can achieve high training throughput with network bandwidths as low as 200 Mb/s.
- Scalability: The approach scales with both the number of nodes and the size of the model, benefiting from increased computation-to-communication ratios in larger models.
Economics Incentives
In a decentralized training setup powered by crypto-based incentives, Swarm Parallelism aligns well with the need to effectively utilize a diverse pool of resources. Nodes can be incentivized to contribute computational power and maintain high availability, with rewards tied to their participation and performance within the swarm. The adaptive nature of Swarm Parallelism ensures that contributions from nodes are maximized, benefiting the overall training process and making efficient use of the incentivization mechanism.
Comparison with Other Approaches
While methods like DiLoCo and Distro focus on reducing communication overhead through local consensus mechanisms and adaptive gradient sharing, Swarm Parallelism tackles the problem by rearchitecting the training paradigm itself. It minimizes the dependency on frequent synchronization by allowing nodes to operate semi-independently within a dynamically adjusting pipeline.
Compared to alternative transformer architectures like Mixtral, Switch Transformers, and DiPaCo, which aim to reduce communication by activating only subsets of the model (e.g., specific experts or modules), Swarm Parallelism offers a more general solution that doesn't rely on model sparsity. Instead, it optimizes the training process at the system level, making it compatible with a wide range of models, including dense architectures.
Practical Implementation and Results
Research has demonstrated that Swarm Parallelism can be effectively used to train large Transformer language models with over 1 billion parameters on preemptible GPUs with limited network bandwidth. By combining the approach with compression strategies, it is possible to achieve high training throughput without the need for specialized high-speed networking infrastructure.
In experiments, Swarm Parallelism showed that increasing the model size can actually decrease the network overhead per device due to the Square-Cube Law. This counterintuitive result highlights the suitability of Swarm Parallelism for training massive models in decentralized environments.
Summary
The key takeaway is that swarm parallelism offers a pathway to truly decentralized AI development. Its adaptability to unreliable and heterogeneous networks, while preserving high computational efficiency, makes it an appealing option for large-scale, collaborative model training. This approach is particularly compelling for those who believe that scaling model size to its maximum potential will result in the highest performance gains.
Verification of Computation
The approaches discussed above assume a somewhat trusted environment, which inherently limits our capacity to defend against malicious actors. However, in real-world deAI applications, it is crucial to acknowledge and address the presence of adversarial entities that may attempt to corrupt models, tamper with data, or otherwise interfere with system integrity. Addressing security concerns in deAI requires multi-layered defenses, with particular focus on cryptographic solutions and trusted hardware environments.
Cryptographic Solutions for Securing Decentralized AI
When it comes to cryptographic solutions for ensuring the safety and reliability of AI operations in decentralized environments, there are a few main approaches that have gained traction:
- Zero-Knowledge Proofs (ZKPs): In the context of deAI, ZKPs can be used to verify that training or inference computations were performed correctly, without requiring verification nodes to see the actual data. This is particularly useful for maintaining privacy in decentralized networks, but it comes at a significant computational cost. The heavy overhead makes ZKPs impractical for real-time AI training or inference due to latency and resource requirements.
- Fully Homomorphic Encryption (FHE): FHE enables computations on encrypted data, allowing models to be trained or evaluated without ever revealing the raw data itself. This promises high levels of data privacy and security, which is beneficial in environments with minimal trust. However, like ZKPs, the major drawback of FHE is its computational complexity. FHE requires an enormous amount of resources, resulting in a massive slowdown compared to unencrypted computation. As a result, it is currently unsuitable for high-performance AI workloads without significant optimization and specialized hardware support.
- Multi-Party Computation (MPC): MPC enables multiple parties to jointly compute a function over their inputs while keeping those inputs private. This approach has been applied to model training, where different nodes collaboratively train a model without sharing their raw datasets. MPC offers improved privacy guarantees, but suffers from increased communication overhead and is generally less efficient compared to conventional centralized training methods.
Hardware-Based Isolation: The Role of Trusted Execution Environments (TEEs)
The promising alternative to purely cryptographic solutions lies in hardware-based isolation, specifically through the use of Trusted Execution Environments (TEEs). TEEs are specialized, secure areas within a processor that guarantee code and data loaded inside are protected with respect to confidentiality and integrity. By leveraging TEEs, we can achieve verified inference and training without incurring the prohibitive computational costs associated with cryptographic methods like ZKP or FHE.
Types of TEEs and Their Applications in deAI
- Conventional TEEs (e.g., Intel SGX, AMD SEV): These TEEs create isolated environments on standard hardware, allowing for secure processing of sensitive data. In the context of deAI, TEEs can be used to verify that AI model inference or training is executed as intended, without exposing model parameters or input data to the rest of the system. This approach allows for confidential model execution in edge nodes or untrusted servers, reducing risks associated with data leakage or model theft. But, conventional TEEs, such as Intel SGX, suffer from a plethora of other issues (such as trusting the hardware vendors).
- Open TEEs (e.g., Keystone, Open Enclave): Open TEEs are emerging alternatives designed to provide more transparency and flexibility. These open-source TEE frameworks aim to alleviate the centralized control issues inherent in conventional TEEs. By offering customizable and verifiable TEE designs, projects like Keystone enable decentralized AI applications to better meet the diverse needs of various stakeholders while fostering trust. Open TEEs also make it easier to audit and extend the hardware’s functionality, reducing reliance on any single hardware vendor and promoting broader decentralization.
Advantages of TEEs in Decentralized AI Projects
- Performance Efficiency: Unlike ZKP or FHE, which are known for their heavy computational overhead, TEEs allow for near-native performance during both model training and inference. This makes TEEs highly suitable for real-time or large-scale AI applications.
- Verified Execution: TEEs provide verifiable evidence that the AI computation was executed correctly, without being tampered with by malicious actors. This is crucial for establishing trust in decentralized environments, where nodes must prove that they have carried out computations as specified.
- Confidentiality of Data and Models: By keeping the data and models within a hardware-isolated enclave, TEEs prevent leakage to untrusted parties, thereby protecting intellectual property and sensitive user information.
- Combining TEEs with Cryptographic Methods: One promising approach is to combine TEEs with cryptographic protocols, such as using TEEs to perform computationally intensive tasks while delegating verification tasks to ZKP. This hybrid approach allows us to balance performance with security, achieving the best of both worlds.
Conclusion
To secure deAI systems, we must take a holistic approach that considers both cryptographic solutions and hardware isolation. While purely cryptographic solutions like ZKPs and FHE offer high levels of security, their computational overhead makes them impractical for many real-time AI applications. TEEs, by contrast, provide an effective compromise between security, performance, and decentralization, especially when enhanced by open-source alternatives and combined with lightweight cryptographic verification mechanisms. At the end of the day, security is economics, and TEE’s are the most cost effective and practical solution.
Moving forward, ongoing developments in open-source TEEs, and hybrid cryptographic-TEE solutions will be pivotal for creating secure, scalable, and decentralized AI systems that can operate in untrusted environments without sacrificing efficiency or privacy.
Future Research
Throughout this report, we have explored numerous approaches that have pushed the boundaries of decentralized training. These discussions should have demonstrated that decentralized training is not only feasible but also holds great potential for advancing the field. Federated Learning, Model Merging, and PCN networks are just some of the verticals of research that are ongoing in the ML world. There are also many unanswered questions that may inhibit the growth of distributed training before being solved, such as verifiable training and coordinated optimizations and governance across a widely distributed network of nodes. While this report was focused on the core design principles necessary to understand the world of deAI there are many talented researchers working on some of these other promising verticals. Some of these other research verticals and novel methodologies for decentralized training will be explored in part 3 of this report.
We are excited about the prospect of working towards a future where AI can be decentralized, open and collaborative, a future where we can push an AI driven-society forwards whilst mitigating the concerns around an AI oligopoly. Furthermore, if you are building in this space, we would love to hear from you, as we are always looking for people who are pushing the boundaries of what we think is possible. We are committed to driving innovation at the cutting edge of crypto.
There are a few questions that we would love to open up for conversation:
- Can we infinitely scale models and expect continuous improvements, or is there a point where scaling reaches a plateau, requiring architectural breakthroughs to further enhance AI capabilities?
- Is Mixture of Experts a viable architecture to compete with densely connected models?
- Can model merging achieve similar results to massive training runs?
- Can Distributed Path Composition act as a viable method for training large scale models?
- Can State Space models or PCN networks eventually compete with the transformer architecture?
- What are approaches we can take to verify computation in an untrusted setup?
Continue to Part 3: deAI – Further Research
Sources:
Links on Hardware Research
Links on Attention Mechanisms and Transformer Models:
- Attention Is All You Need (Introduced Transformer architecture) Link
- Neural Machine Translation by Jointly Learning to Align and Translate (Introduced Attention mechanism) Link
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Link
- Gated Attention Networks for Sequence Data Link
- The Illustrated Transformer (Great visualization and explanation) Link
- Transformers: State-of-the-Art Natural Language Processing Link
- XLNet: Generalized Autoregressive Pretraining for Language Understanding Link
- GPT-3: Language Models are Few-Shot Learners Link
- Reformer: The Efficient Transformer (Improves Transformer efficiency) Link
- A Gentle Introduction to Positional Encoding Link
Links on Optimizers:
- Adam: A Method for Stochastic Optimization Link
- Decoupled Weight Decay Regularization (AdamW) Link
- SGD with Momentum: A Simple and Effective Improvement Over Basic SGD Link
- RMSProp: Divide the Gradient by a Running Average of its Recent Magnitude Link
- AMSGrad: Improving Generalization in Adam Link
- AdaGrad: Adaptive Subgradient Methods for Online Learning and Stochastic Optimization Link
- AdaBelief: Adaptive Belief Optimizer Link
- Lookahead Optimizer: K Steps Forward, 1 Step Back Link
- RAdam: Rectified Adam Optimizer Link
- AdaBound: Adaptive Gradient Methods with Dynamic Bound of Learning Rate Link
- Fp8 Link
Links on 3D Parallelism in Transformer Architectures:
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism Link
- Megatron LM Blog Nvidia Link
- Efficient Large-Scale Language Model Training with Pipeline Parallelism Link
- DeepSpeed: Extreme-Scale Model Training (Combining pipeline and data parallelism) Link
- ZeRO: Memory Optimization for Large-Scale Distributed Training (3D parallelism for memory efficiency) Link
- GShard: Scaling Giant Models with Conditional Computation Link
- Parallel Transformers: Spreading Large Transformers Across Multiple Devices Link
- Mesh TensorFlow: Model Parallelism Made Easier Link
- Tensor Parallelism at Scale (Tensor-slicing and distributed model training) Link
- PipeDream: General Pipeline Parallelism for DNN Training Link
- GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism Link
Links on Data Parallelism Specifically:
- PyTorch Distributed Communication Package (DistributedDataParallel)[link]
- Horovod Documentation (Distributed Training Framework)[link]
- TensorFlow Distributed Training with MirroredStrategy[link]
- Centralized and Distributed Parameter Server for Distributed Machine Learning[link]
- Efficient Large-Scale Distributed Training via Gradient Compression[link]
- NVIDIA NCCL (NVIDIA Collective Communication Library)[link]
- Horovod: Distributed Deep Learning Framework for TensorFlow, Keras, PyTorch, and MXNet [link]
- Overlapping Communication with Computation in Hybrid MPI+Threads Programming Models [link]
- Gradient Accumulation in Large-Scale Deep Learning [link]
- Efficient Distributed Data-Parallel Training Using Small Batch Sizes with Model Averaging [link]
Links on Alternative Transformer Architectures:
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity Link
- DiPaCo: Distributed and Parallel Transformer Architectures Link
- Mixture of Experts: Sparsely-Gated Deep Learning Models Link
- GShard: Scaling Giant Models with Conditional Computation Link
- Reformer: The Efficient Transformer (Reducing complexity of transformers) Link
- Sparse Transformer (A transformer with sparse attention) Link
- Longformer: The Long-Document Transformer (Scales attention for longer contexts) Link
- Linformer: Self-Attention with Linear Complexity Link
- Perceiver: General Perception with Iterative Attention Link
- Routing Transformers (Dynamic routing to improve sequence processing) Link
- Peering Inside GPT4 MOE model Link
Misc
Disclosure: Unless otherwise indicated, the views expressed in this post are solely those of the author(s) in their individual capacity and are not the views of Big Brain Holdings or its affiliates. Certain information contained herein may have been obtained from third-party sources, including from portfolio companies of funds managed by Big Brain Holdings. Big Brain Holdings believes that the information provided is reliable but has not independently verified the non-material information and makes no representations about the enduring accuracy of the information or its appropriateness for a given situation. Charts and graphs provided within are for informational purposes solely and should not be relied upon when making any investment decision. Any projections, estimates, forecasts, targets, prospects, and/or opinions expressed in this blog are subject to change without notice and may differ or be contrary to opinions expressed by others.
The content is provided for informational purposes only, and should not be relied upon as the basis for an investment decision, and is not, and should not be assumed to be, complete. The contents herein are not to be construed as legal, business, or tax advice. You should consult your own advisors for those matters. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services. Any investments or portfolio companies mentioned, referred to, or described are not representative of all investments in vehicles managed by Big Brain Holdings, and there can be no assurance that the investments will be profitable or that other investments made in the future will have similar characteristics or results.
This blog does not constitute investment advice or an offer to sell or a solicitation of an offer to purchase any limited partner interests in any investment vehicle managed by Big Brain Holdings. An offer or solicitation of an investment in any Big Brain Holdings investment vehicle will only be made pursuant to an offering memorandum, limited partnership agreement and subscription documents, and only the information in such documents should be relied upon when making a decision to invest.
Past performance does not guarantee future results. There can be no guarantee that any Big Brain Holdings investment vehicle’s investment objectives will be achieved, and the investment results may vary substantially from year to year or even from month to month. As a result, an investor could lose all or a substantial amount of its investment. Investments or products referenced in this blog may not be suitable for you or any other party.